2022. 12. 17. 22:11ㆍProject/프로야구 분석하기
https://sports.news.naver.com/kbaseball/schedule/index?date=20221108&month=04&year=2022&teamCode=
네이버 스포츠
스포츠의 시작과 끝!
sports.news.naver.com
1. 네이버 스포츠 야구 일정 주소창 확인
https://sports.news.naver.com/kbaseball/schedule/index?date=20221108&month=04&year=2022&teamCode=
- "date="는 위에 보이는 날짜를 뜻함
- "month=" 는 일정에 보이는 달을 의미함
- "year=" 는 년도, "teamCode="해당 팀 일정만 볼 수 있는 것
- 2022년도의 전체적인 데이터 수집을 목표로 하기 때문에 일단 teamCode와 date, year 파라미터는 제외하고 month만 프로야구가 진행되는 4~10월 까지 숫자만 바꿔가며 데이터를 받아온다.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
# 야구 시즌 4~ 10월 까지
for i in range(4, 11):
# 월별 KBO 일정
url = f'https://sports.news.naver.com/kbaseball/schedule/index?month={i}&year=2022'
driver.get(url)
driver.maximize_window()
driver.implicitly_wait(5)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')2. 개발자 모드 확인
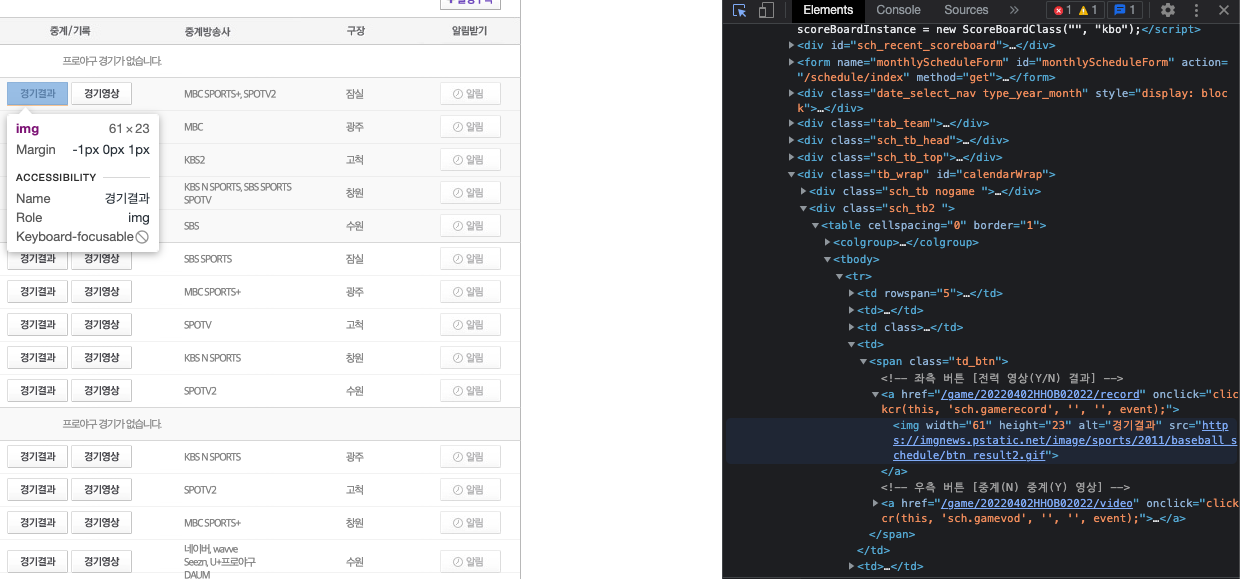
- 경기결과로 가야되기 때문에 확인을 하면 span class= "td_btn"에 있는 a에 href 주소를 가져와야됨
- 모든 span class= "td_btn"를 가져와서 하나씩 확인
- 가져온 주소를 https://m.sports.naver.com 뒤에 추가하며 해당주소로 들어감
- game_id는 a에 href 주소에서 "/"를 기준으로 2 인덱스에 위치
- game_id앞에 4자리가 2022가 아니라면 플레이오프 경기이기 때문에 정규시즌 경기만 다룰거기 때문에 제외시킴
# 경기결과 창으로 가기
for i in soup.find_all("span", {"class":"td_btn"}):
record_url = f'https://m.sports.naver.com{i.find("a")["href"]}'
game_id = i.find("a")['href'].split("/")[2]
# 플레이오프 경기들은 제외
if game_id[:4] != '2022':
continue
driver.get(record_url)
time.sleep(1.5)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')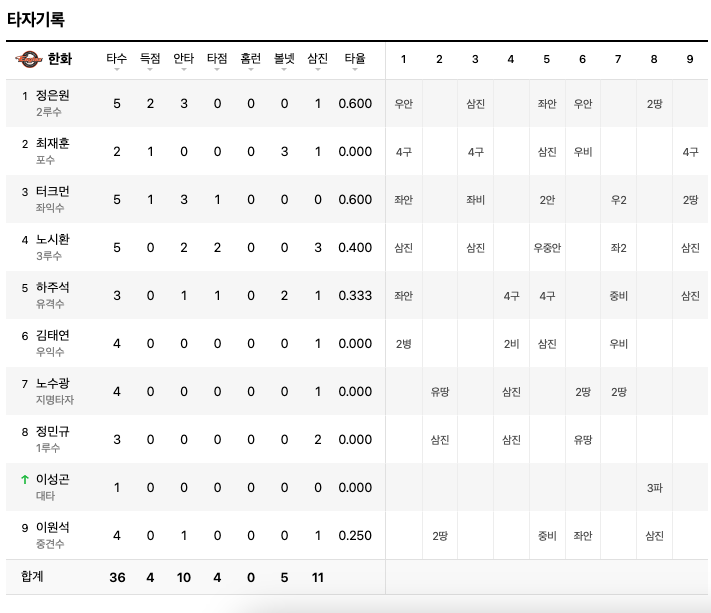
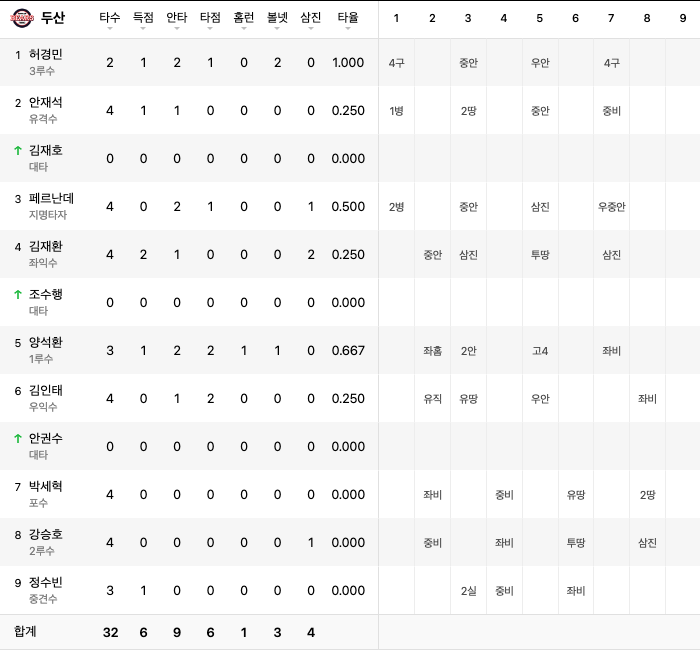
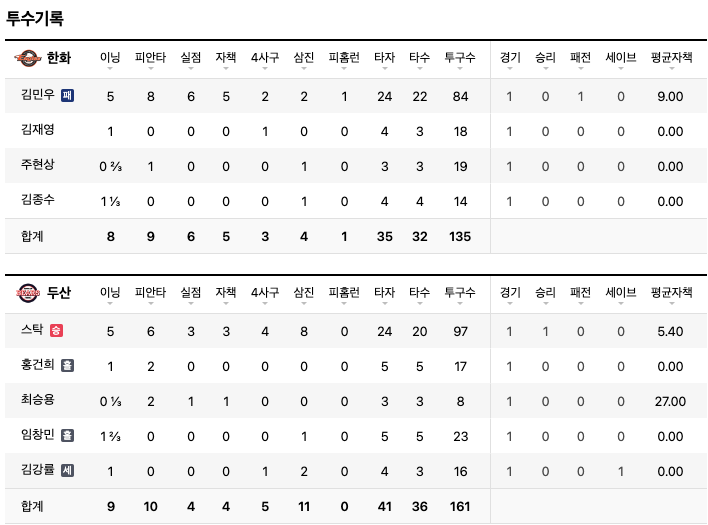
- 가져와야될 데이터 4개의 테이블 홈 타자 기록, 어웨이 타자 기록, 홈 투수 기록, 어웨이 투수 기록
- 각각에 테이블에서 팀이름을 가져옴
team = [w.text for w in soup.find_all('span', {'class' : 'PlayerRecord_team_name__1cS9X'})]- tbody 위에서 3개는 제외하고 그 다음부터 인덱스 번호를 가져와서 0, 1은 타자 데이터 2, 3은 투수 데이터
# table 0, 1은 타자 데이터 2, 3은 투수 데이터로 구분해서 따로 저장
for table, j in enumerate(soup.find_all('tbody')[3:]):
# 타자
if table == 0 or table == 1:
# 테이블에서 맨 아래 데이터는 제거
for k in j.find_all('tr')[:-1]:
ground_ball, line_driver, pop_fly = 0, 0, 0 # 뜬공, 땅볼, 직선타
right, center, left = 0, 0, 0
double_play = 0
player_id = k.find("a")['href'].split("=")[-1]
hitter_name = k.find('span', {'class' : 'PlayerRecord_name__1W_c0'}).text # 타자 이름
hitter_position = k.find('span', {'class' : 'PlayerRecord_position__3SBbd'}).text # 타자 포지션
if hitter_position == '대타': # 대타 일때
batter_num = k.find('span', {'class' : 'PlayerRecord_icon_substitution__h3DpJ'}).text # 타순이 아닌 교체로 표시
else:
batter_num = k.find('span', {'class' : 'PlayerRecord_bat_order__2gZ-S'}).text # 타자 타순
hitter_data = [w.text for w in k.find_all('td')[:8]] # 타자 데이터 8개
for w in k.find_all('td', {'class': 'PlayerRecord_col_inn__1bqTN'}): # 타수 상세 기록
if w.text != '':
for hit in w.text.split("/"): # 한 회에 여러 타석을 섰을 때
if hit != '':
hitter_location(hit)
fly_ground_line(hit)
double_play_count(hit)
# parquet으로 변형 하기 위해 column 위주로 데이터를 저장
hitter.append({'game_id' : game_id, 'player_id' : player_id, 'batter_num' : batter_num, 'name' : hitter_name,
'position' : hitter_position, 'team' : team[table], 'AB' : hitter_data[0], 'R' : hitter_data[1],
'H' : hitter_data[2], 'RBI' : hitter_data[3], 'HR': hitter_data[4], 'BB' : hitter_data[5],
'SO' : hitter_data[6], 'AVG' : hitter_data[7], 'ground_ball' : ground_ball, 'line_driver' : line_driver,
'pop_fly' : pop_fly, 'right' : right, 'center' : center, 'left' : left, 'double_play' : double_play})
# 투수 데이터
else:
for k in j.find_all('tr')[1:-1]:
player_id = k.find("a")['href'].split("=")[-1]
name = k.find('span', {'class' : 'PlayerRecord_name__1W_c0'}).text # 투수 이름
if k.find('em') != None: # 투수 상세 기록 승리, 패배, 홀드, 세이브 표시
record = k.find('em').text
else:
record = None
pitcher_data = [w.text for w in k.find_all('td')] # 투수 데이터
# parquet으로 변형 하기 위해 column 위주로 데이터를 저장
pitcher.append({'game_id' : game_id, 'player_id' : player_id, 'name' : name, 'record': record, 'team' : team[table], 'IP' : pitcher_data[0], 'H' : pitcher_data[1],
'R' : pitcher_data[2], 'ER' : pitcher_data[3], 'BB' : pitcher_data[4], 'SO' : pitcher_data[5], 'HR' : pitcher_data[6],
'HITTER' : pitcher_data[7], 'AB' : pitcher_data[8], 'PIT' : pitcher_data[9], 'G' : pitcher_data[10], 'W' : pitcher_data[11],
'L' : pitcher_data[12], 'SV' : pitcher_data[13], 'ERA' : pitcher_data[14]})
driver.back()3. parquet 형식으로 HDFS에 저장
hitter_file_path = f"hdfs://localhost:9000/user/jjwani/KBO/2022/hitter.parquet"
# HDFS에 타자 데이터 파일 저장
hitter_df = spark.createDataFrame(hitter)
hitter_df.write.mode('overwrite').parquet(hitter_file_path)
pitcher_file_path = f"hdfs://localhost:9000/user/jjwani/KBO/2022/pitcher.parquet"
# HDFS에 투수 데이터 파일 저장
pitcher_df = spark.createDataFrame(pitcher)
pitcher_df.write.mode('overwrite').parquet(pitcher_file_path)