[Day 32] Sprint Review
2022. 3. 8. 19:19ㆍAI/Codestates
728x90
반응형
코딩부트캠프 | 코드스테이츠 - 비전공생도 개발자가 될 수 있습니다
코딩부트캠프를 찾는다면? 개발자로 커리어 전환을 위한 책임있는 코딩 교육 기관! 서비스 기획자, 그로스 마케터, 데이터 사이언티스트 등 다양한 전문 커리어에 도전하세요. 취업 성공의 후기
www.codestates.com
Summary
- 분류 평가지표
- 모델의 예측값에 Threshold가 적용되어 최종적으로 분류된 결과를 평가하는 지표들입니다.
- Threshold가 바뀔 경우 평가 지표의 값도 바뀝니다.
- TP / TN / FP / FN
예측 1 예측 0 실제 1 TP FN 실제 0 FP TN - TP == True Positive == 진짜 양성 == 실제 1, 예측 1
- TN == True Negative == 진짜 음성 == 실제 0, 예측 0
- FP == False Positive == 가짜 양성 == 실제 0, 예측 1 == 모델이 가짜로 1이라고 한 것
- FN == False Negative == 가짜 음성 == 실제 1, 예측 0 == 모델이 가짜로 0이라고 한 것
- 결정트리 ( Decision Trees ) : 어떤 조건에 대해서 boolean으로 대답하는것
- 분류와 회귀문제 모두 적용 가능!
- 모델을 만들 때 독립 변수 Input의 Type은 범주형, 연속혁 ( 수치형 ) 둘다 가능!
- 분할 기준은 불순도를 비교하고 가장 적게 나오는 분기점!
- 트리 학습 비용함수
- 지니불순도
- 엔트로피
- 파이프라인 사용
from ipywidgets import interact
from sklearn.metrics import f1_score
from sklearn.tree import DecisionTreeClassifier
from category_encoders import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
def thurber_tree(max_depth=1):
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True),
SimpleImputer(),
DecisionTreeClassifier(max_depth = max_depth, random_state=2))
pipe.fit(X_train, y_train)
y_pred = pipe.predict(X_val)
print('검증세트정확도: ', pipe.score(X_val, y_val))
print('F1-score: ', f1_score(y_val, y_pred))
interact(thurber_tree, max_depth=(1,50,1));- 특성중요도 그래프
importances = pd.Series(model_dt.feature_importances_, encoded_columns)
plt.figure(figsize=(10,30))
importances.sort_values().plot.barh()
- 앙상블 방법 : 한 종류의 데이터로 여러 머신러닝 학습모델을 만들어 그 모델들의 예측결과를 다수결이나 평균을 내어 예측하는 방법
- Random Forests
- 버깅 ( Bagging , Bootstrap Aggregting ) : Bootstrap으로 훈련된 데이터를 다시 합치는 과정
- 부스스트랩 ( Bootstrap ) 샘플링 : 원본 데이터에서 샘플링을 하는데 복원추출을 한다는 것
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score
pipe_ord = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier(random_state=2, n_jobs=-1, oob_score=True)
)
pipe_ord.fit(X_train, y_train)
print('검증 정확도', pipe_ord.score(X_val, y_val))- 원핫인코딩 VS 순서형 인코딩
- OneHotEncoding : 카테고리 수에 따라 새로운 특성 생성 -> 카테고리가 많이 없고, 명목형 데이터 일 때
- OrdinalEncoding : 열 개수는 그대로 유지 ( 1개 ) 카테고리 별 중요도가 설정됨 -> 카테고리 별로 중요도가 다를 때
- Confusion Matrix
from sklearn.metrics import plot_confusion_matrix
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
pcm = plot_confusion_matrix(pipe, X_val, y_val,
cmap=plt.cm.Purples,
ax=ax);
plt.title(f'Confusion matrix, n = {len(y_val)}', fontsize=15)
plt.show()
- 정밀도 ( Precision ) : Positive로 예측한 경우 중 올바르게 Positive를 맞춘 비율
- 재현율 ( Recall ) : 실제 Positive인 것 중 올바르게 Positive를 맞춘 비율
- F1-Score : 정밀도와 재현율의 조화평균이다.
- 임계값
from ipywidgets import interact, fixed
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report
def explore_threshold(y_true, y_pred_proba, threshold=0.5):
y_pred = y_pred_proba >= threshold
vc = pd.Series(y_pred).value_counts()
ax = sns.histplot(y_pred_proba, kde=True)
ax.axvline(threshold, color='red')
ax.set_title(f'# of target, 1={vc[1]}, 0={vc[0]}')
plt.show()
print(classification_report(y_true, y_pred))
interact(explore_threshold,
y_true=fixed(y_val),
y_pred_proba=fixed(y_pred_proba),
threshold=(0, 1, 0.01));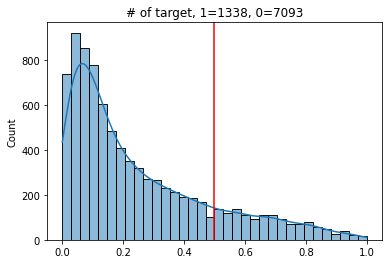
임계값에 따른 그래프
- ROC ( Receiver Operating Characteristic ) : 머신러닝의 이진 분류 모델의 예측 성능을 판단하는 중요한 평가지표
fpr, tpr, thresholds = roc_curve(y_val, y_pred_proba)
roc = pd.DataFrame({
'FPR(Fall-out)': fpr,
'TPRate(Recall)': tpr,
'Threshold': thresholds
})
rocplt.scatter(fpr, tpr)
plt.title('ROC curve')
plt.xlabel('FPR(Fall-out)')
plt.ylabel('TPR(Recall)');
- AUC ( Area Under Curve ) : ROC 곡선 밑의 면적을 구한 것
from sklearn.metrics import roc_auc_score
auc_score = roc_auc_score(y_val, y_pred_proba)
auc_score- 교차검증 ( Cross - Validation )
- 시계열 ( Time Series ) 데이터에 적합하지 않음
- TargetEncoder
- OrdinalEncoder 보다 요즘 성능이 좋음.
- 하이퍼파라미터 튜닝
- 최적화 : 훈련 데이터로 더 좋은 성능을 얻기 위해 모델을 조정하는 과정
- 일반화 : 처음 본 데이터로 얼마나 좋은 성능을 내는지
- RandomizedSearchCV : 무작위
from sklearn.pipeline import make_pipeline
from category_encoders import OrdinalEncoder
from sklearn.impute import SimpleImputer
from sklearn.ensemble import RandomForestClassifier
from scipy.stats import randint, uniform
from sklearn.model_selection import RandomizedSearchCV
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier(random_state=2)
)
dists = {
'simpleimputer__strategy': ['mean', 'median'],
'randomforestclassifier__n_estimators': randint(50, 500),
'randomforestclassifier__max_depth': [5, 10, 15, 20, None],
'randomforestclassifier__max_features': uniform(0, 1) # max_features
}
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=20,
cv=3,
scoring='f1',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train)
print('최적 하이퍼파라미터: ', clf.best_params_)
- GridSearchCV : 전체
from category_encoders import TargetEncoder
from sklearn.model_selection import GridSearchCV
pipe = make_pipeline(
TargetEncoder(),
SimpleImputer(),
RandomForestClassifier(random_state=2,class_weight='balanced')
)
dists = {
'simpleimputer__strategy': ['mean', 'median'],
'randomforestclassifier__n_estimators': [10, 50, 100],
'randomforestclassifier__max_depth': [10, 50, 100],
'randomforestclassifier__max_features': ['auto','log2'],
'randomforestclassifier__min_samples_leaf' : [1, 3, 5]
}
clf = GridSearchCV(
pipe,
param_grid=dists,
cv=3,
scoring='f1',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train)
print('최적 하이퍼파라미터: ', clf.best_params_)728x90
반응형
'AI > Codestates' 카테고리의 다른 글
| [Day 34] Data Wrangling (0) | 2022.03.15 |
|---|---|
| [Day 33] Choose your ML problems (0) | 2022.03.10 |
| [Day 31] Model Selection (0) | 2022.03.08 |
| [Day 30] Evaluation Metrics for Classification (0) | 2022.03.04 |
| [Day 29] Random Forests (0) | 2022.03.03 |