Book/하둡 완벽 가이드
MapReduce
JooJaeHwan
2022. 10. 5. 23:14
728x90
반응형
MapReduce 란?
- 2004년에 구글에서 발표한 데이터 처리 알고리즘
- Hadoop의 MapReduce는 구글에서 발표한 MapReduce 논문을 자바로 구현한 애플리케이션
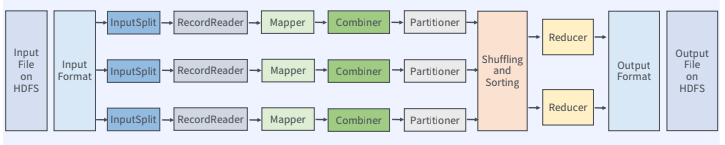
MapReduce 처리과정
▶ InputFormat

▶ SequenceFile
- Hadoop에서 제공하는 Binary 파일 포맷
- Key - Value pair로 구성
- Binary로 저장되어 있어서 속도가 빠름
- 압축에 따른 포맷
- Uncompressed
- Record - Compressed : 값만 압축
- Block - Compressed : 키와 값 모두 블록에 압축
- 용도
- 작은 압축 파일들을 모아 SeqeunceFile로 묶어서 사용
- 압축을 통해 Shuffling의 트래픽 양을 줄이는데 사용
▶ InputSplit VS Block

■ Block

■ InputSplit
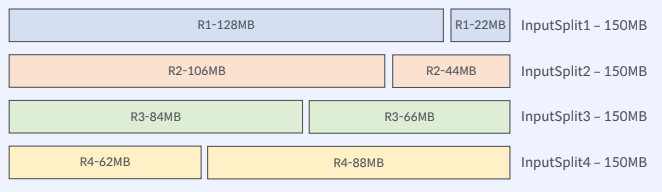
▶ InputSplit
- 맵의 입력으로 들어가는 데이터를 분할하는 방식 정의
▶ RecordReader
- InputSplit를 읽어오는 역할
▶ Combiner
- Mapper의 결과를 추가적으로 처리해서 Reducer로 전송되는 데이터를 줄여주는 역할
- 있을 수도 있고 없을 수도 있음
▶ Partitioner
- Map의 결과를 어떤 Reduce에 전달할지를 결정하는 역할
▶ Shuffling and Sorting
- Map의 중간결과 파일을 Reducer로 전달하고 Key를 기준으로 정렬하는 과정
▶ OutputFormat
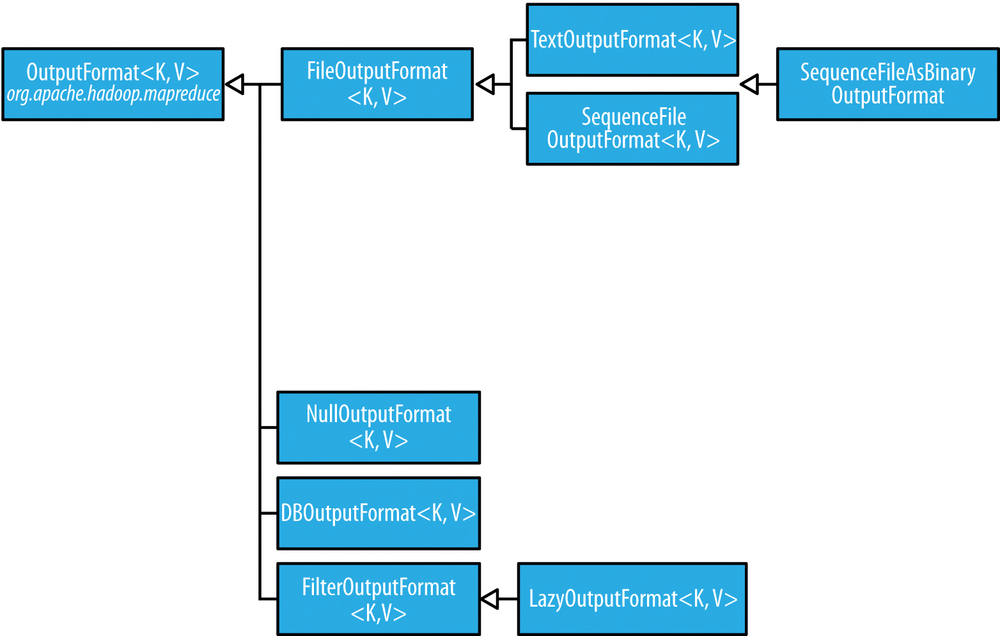
MapReduce Job
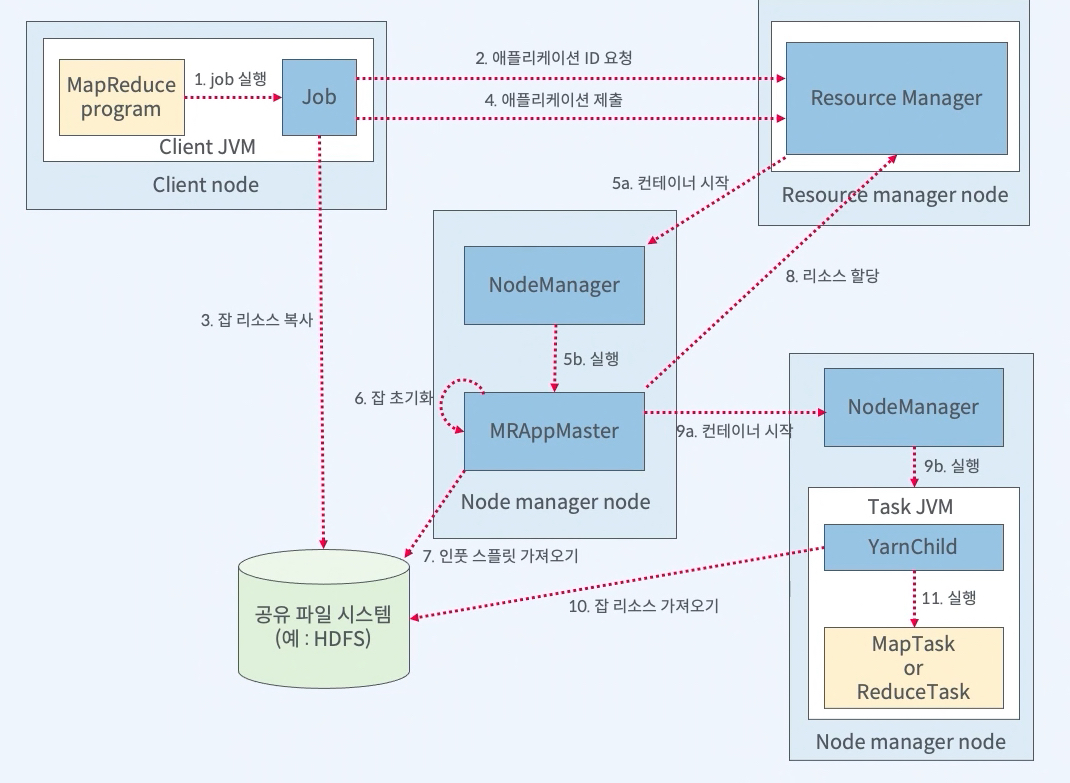
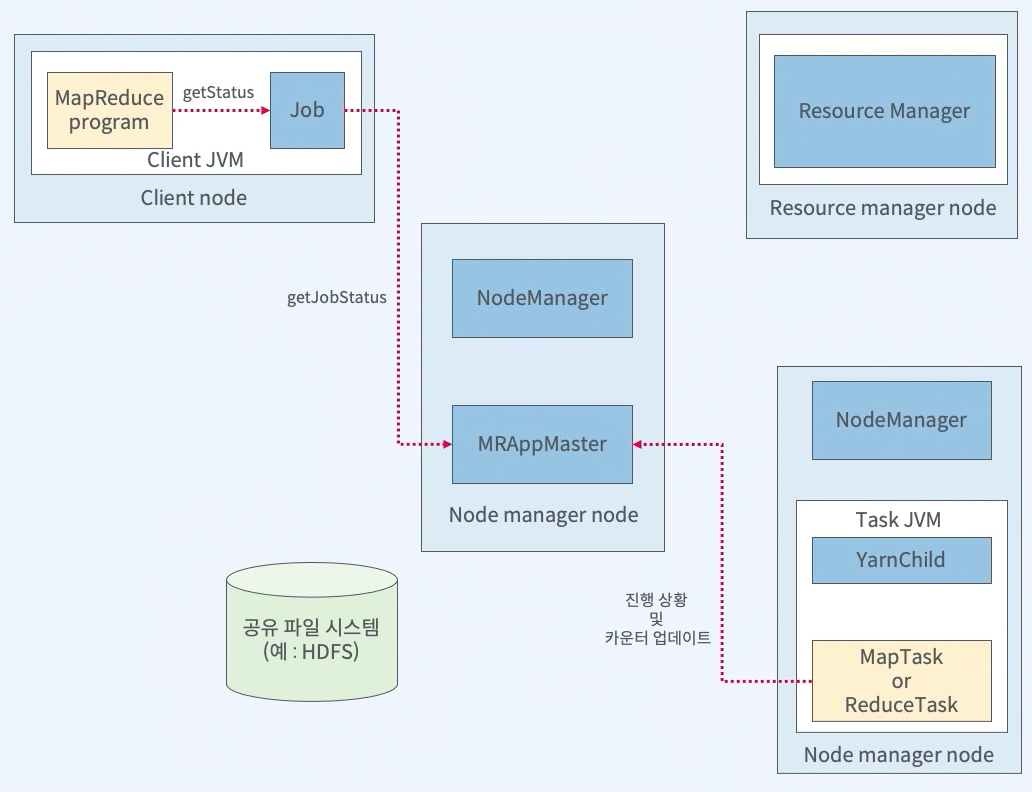
MapReduce Job 완료 후
- 마지막 태스크가 완료되면 Application Master가 Job 상태를 성공으로 변경
- 클라이언트에서 실행한 waitforcompletion 메서드가 반환
- Job통계와 카운터와 같은 메세지 출력
- 히스토리 서버에 잡 정보를 기록
728x90
반응형