[Deep Learning - NLP] Distributed Representation
2022. 5. 6. 23:28ㆍAI/Codestates
728x90
반응형
원핫 인코딩이란?
전체 단어의 크기만큼의 차원을 가지고 해당되는 단어 1 아니면 0 으로 표현하는 인코딩 방법
▶ 단점
단어간의 유사성을 알 수 없음
임베딩 ( Embedding ) 이란?
길이가 고정된 연속적인 값을 갖는 벡터로 변환하는 것
▶ Word2Vec
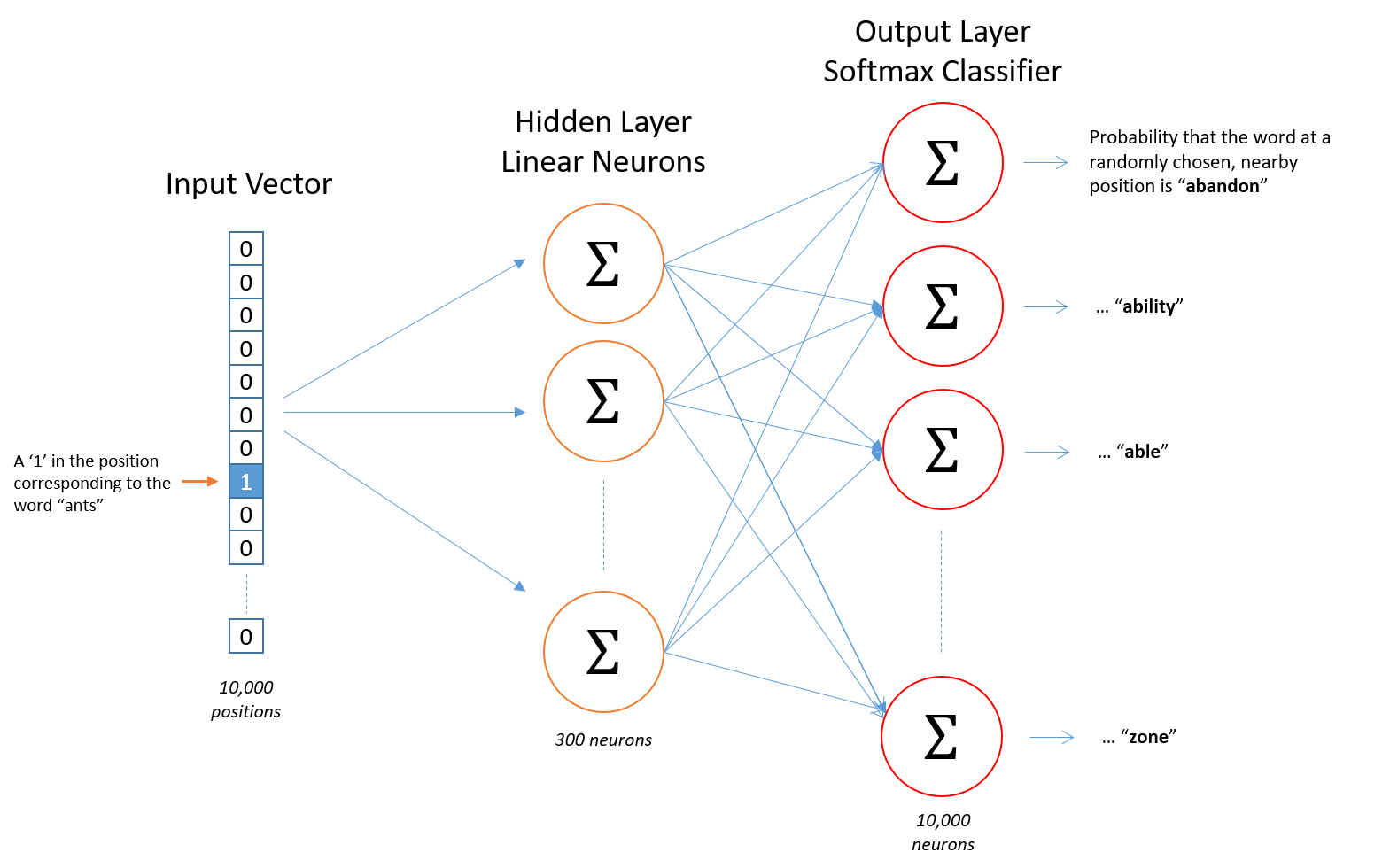
→ CBoW
주변단어에서 중심단어를 예측
→ Skip - gram
중심단어에서 주변단어를 예측
- 입력 : 원핫 인코딩 된 단어 벡터
- 은닉층 : 임베딩 벡터의 차원 수 만큼 노드로 구성된 은닉층 1개
- 출력층 : 활성화 함수, 소프트 맥스 함수 사용
→ 단어
OOV ( Out-Of-Vocabulary ) 문제 : 모르는 단어로 인해 문제를 푸는 것이 까다로워지는 상황
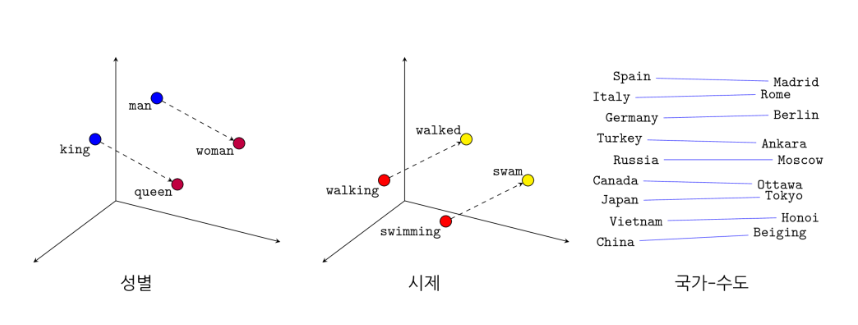
→ 임베딩한 단어 벡터의 특징
- man-woman 관계와 king-queen의 관계 → 의미적 관계를 표현 할 수 있음
- wallking-walked 관계와 swimming-swam의 관계 → 문법적, 구조적 관계 표현 가능
▶ Word2Vec 코드
import gensim.downloader as api
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from keras.preprocessing import sequence
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.preprocessing.text import Tokenizer
wv = api.load('word2vec-google-news-300')
tokenizer = Tokenizer(num_words = 1000)
tokenizer.fit_on_texts(X_train)
X_train_encoded = tokenizer.texts_to_sequences(X_train)
X_test_encoded = tokenizer.texts_to_sequences(X_test)
vocab_size = len(tokenizer.word_index) + 1
X_train = pad_sequences(X_encoded, maxlen=150, padding = 'post')
embedding_matrix = np.zeros((vocab_size, 300))def get_vector(word):
"""
해당 word가 word2vec에 있는 단어일 경우 임베딩 벡터를 반환
"""
if word in wv:
return wv[word]
else:
return None
for word, i in tokenizer.word_index.items():
temp = get_vector(word)
if temp is not None:
embedding_matrix[i] = tempmodel = Sequential([
Embedding(vocab_size, 300, weights = [embedding_matrix], input_length = 150, trainable = False),
GlobalAveragePooling1D(),
Dense(1, activation = 'sigmoid')
])
model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
model.fit(X_train, y_train, batch_size = 64, epochs = 10, validation_split = 0.2)model.evaluate(X_test, y_test, verbose=2)▶ 케라스 기본 임베딩 벡터
embedding_dim = 200
model2 = Sequential([
Embedding(vocab_size, embedding_dim, input_length = 150),
GlobalAveragePooling1D(),
Dense(1, activation = 'sigmoid')
])
model2.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])
model2.fit(X_train, y_train, batch_size = 64, epochs = 10, validation_split = 0.2)model2.evaluate(X_test, y_test, verbose=2)
728x90
반응형
'AI > Codestates' 카테고리의 다른 글
| [Deep Learning - NLP] Transformer (0) | 2022.05.10 |
|---|---|
| [Deep Learning - NLP] Language Modeling With RNN (0) | 2022.05.09 |
| [Deep Learning - NLP] Count-based Representation (0) | 2022.05.04 |
| [Day 71] Sprint Review (0) | 2022.05.04 |
| [Deep Learning] Hyperparameter Tuning (0) | 2022.05.02 |