[Deep Learning - NLP] Transformer
2022. 5. 10. 21:30ㆍAI/Codestates
728x90
반응형
Transformer란?
Attention 매커니즘을 극대화 시킨 모델

▶ Encoder Sub-layer
Mult - Head ( Self ) Attention과 Feed Forward 두 개의 층으로 구성
def encoder_layer(dff, d_model, num_heads, dropout, name="encoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
# 인코더는 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask")
# 멀티-헤드 어텐션 (첫번째 서브층 / 셀프 어텐션)
attention = MultiHeadAttention(
d_model, num_heads, name="attention")({
'query': inputs, 'key': inputs, 'value': inputs, # Q = K = V
'mask': padding_mask # 패딩 마스크 사용
})
# 드롭아웃 + 잔차 연결과 층 정규화
attention = tf.keras.layers.Dropout(rate=dropout)(attention)
attention = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(inputs + attention)
# 포지션 와이즈 피드 포워드 신경망 (두번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 드롭아웃 + 잔차 연결과 층 정규화
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention + outputs)
return tf.keras.Model(
inputs=[inputs, padding_mask], outputs=outputs, name=name)'''
인코더 쌓기
'''
def encoder(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name="encoder"):
inputs = tf.keras.Input(shape=(None,), name="inputs")
# 인코더는 패딩 마스크 사용
padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask")
# 포지셔널 인코딩 + 드롭아웃
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
# 인코더를 num_layers개 쌓기
for i in range(num_layers):
outputs = encoder_layer(dff=dff, d_model=d_model, num_heads=num_heads,
dropout=dropout, name="encoder_layer_{}".format(i),
)([outputs, padding_mask])
return tf.keras.Model(
inputs=[inputs, padding_mask], outputs=outputs, name=name)▶ Decoder Sub-layer
Masked Multi - Head ( Self ) Attention과 Mult - Head ( Encoder - Decoder ) Attention, Feed Forword 세개의 층으로 구성
def decoder_layer(dff, d_model, num_heads, dropout, name="decoder_layer"):
inputs = tf.keras.Input(shape=(None, d_model), name="inputs")
enc_outputs = tf.keras.Input(shape=(None, d_model), name="encoder_outputs")
# 룩어헤드 마스크(첫번째 서브층)
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name="look_ahead_mask")
# 패딩 마스크(두번째 서브층)
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 멀티-헤드 어텐션 (첫번째 서브층 / 마스크드 셀프 어텐션)
attention1 = MultiHeadAttention(
d_model, num_heads, name="attention_1")(inputs={
'query': inputs, 'key': inputs, 'value': inputs, # Q = K = V
'mask': look_ahead_mask # 룩어헤드 마스크
})
# 잔차 연결과 층 정규화
attention1 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention1 + inputs)
# 멀티-헤드 어텐션 (두번째 서브층 / 디코더-인코더 어텐션)
attention2 = MultiHeadAttention(
d_model, num_heads, name="attention_2")(inputs={
'query': attention1, 'key': enc_outputs, 'value': enc_outputs, # Q != K = V
'mask': padding_mask # 패딩 마스크
})
# 드롭아웃 + 잔차 연결과 층 정규화
attention2 = tf.keras.layers.Dropout(rate=dropout)(attention2)
attention2 = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(attention2 + attention1)
# 포지션 와이즈 피드 포워드 신경망 (세번째 서브층)
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention2)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)
# 드롭아웃 + 잔차 연결과 층 정규화
outputs = tf.keras.layers.Dropout(rate=dropout)(outputs)
outputs = tf.keras.layers.LayerNormalization(
epsilon=1e-6)(outputs + attention2)
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)'''
디코더 쌓기
'''
def decoder(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name='decoder'):
inputs = tf.keras.Input(shape=(None,), name='inputs')
enc_outputs = tf.keras.Input(shape=(None, d_model), name='encoder_outputs')
# 디코더는 룩어헤드 마스크(첫번째 서브층)와 패딩 마스크(두번째 서브층) 둘 다 사용.
look_ahead_mask = tf.keras.Input(
shape=(1, None, None), name='look_ahead_mask')
padding_mask = tf.keras.Input(shape=(1, 1, None), name='padding_mask')
# 포지셔널 인코딩 + 드롭아웃
embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)
embeddings *= tf.math.sqrt(tf.cast(d_model, tf.float32))
embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)
outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)
# 디코더를 num_layers개 쌓기
for i in range(num_layers):
outputs = decoder_layer(dff=dff, d_model=d_model, num_heads=num_heads,
dropout=dropout, name='decoder_layer_{}'.format(i),
)(inputs=[outputs, enc_outputs, look_ahead_mask, padding_mask])
return tf.keras.Model(
inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],
outputs=outputs,
name=name)▶ Positional Encoder ( 위치 인코딩 )
단어의 상대적인 위치 정보를 만드는 과정
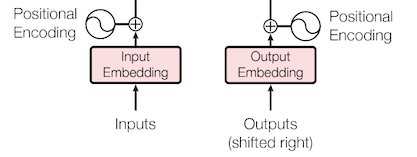
class PositionalEncoding(tf.keras.layers.Layer):
def __init__(self, position, d_model):
super(PositionalEncoding, self).__init__()
self.pos_encoding = self.positional_encoding(position, d_model)
def get_angles(self, position, i, d_model):
angles = 1 / tf.pow(10000, (2 * (i // 2)) / tf.cast(d_model, tf.float32))
return position * angles
def positional_encoding(self, position, d_model):
angle_rads = self.get_angles(
position=tf.range(position, dtype=tf.float32)[:, tf.newaxis],
i=tf.range(d_model, dtype=tf.float32)[tf.newaxis, :],
d_model=d_model)
# 배열의 짝수 인덱스(2i)에는 사인 함수 적용
sines = tf.math.sin(angle_rads[:, 0::2])
# 배열의 홀수 인덱스(2i+1)에는 코사인 함수 적용
cosines = tf.math.cos(angle_rads[:, 1::2])
angle_rads = np.zeros(angle_rads.shape)
angle_rads[:, 0::2] = sines
angle_rads[:, 1::2] = cosines
pos_encoding = tf.constant(angle_rads)
pos_encoding = pos_encoding[tf.newaxis, ...]
print(pos_encoding.shape)
return tf.cast(pos_encoding, tf.float32)
def call(self, inputs):
return inputs + self.pos_encoding[:, :tf.shape(inputs)[1], :]Attention이란?
인코더에서의 전체 입력 문장을 다시 한 번 참고하는 것
▶ Self - Attention
→ 쿼리 : 분석 하고자 하는 단어에 가중치 벡터
→ 키 : 각 단어가 쿼리에 해당하는 단어와 얼마나 연관있는지를 비교하기 위한 가중치 벡터
→ 벨류 : 각 단어의 의미를 살려주기 위한 가중치 벡터
dict = {"a" : 1} # Key "a", Value 1
dict["a"] # Query▶ Multi - Head Attention
여러 개의 Attention 매커니즘을 동시에 병렬적으로 실행
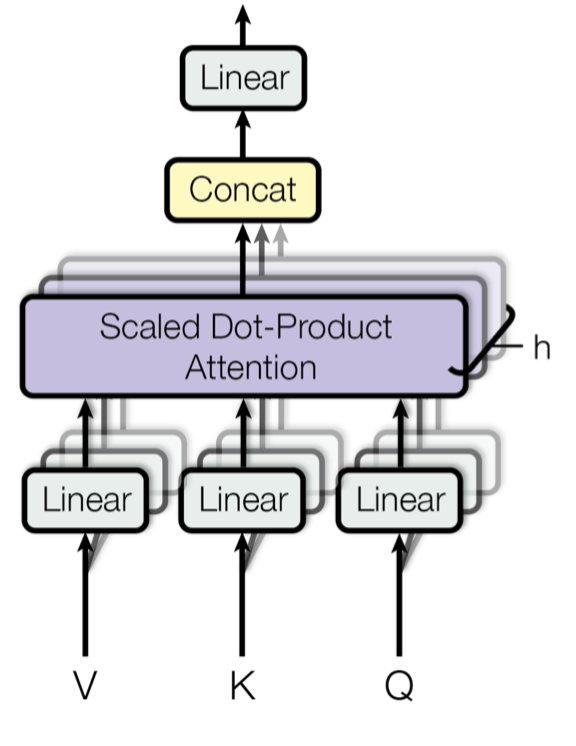
def scaled_dot_product_attention(query, key, value, mask):
# query 크기 : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
# key 크기 : (batch_size, num_heads, key의 문장 길이, d_model/num_heads)
# value 크기 : (batch_size, num_heads, value의 문장 길이, d_model/num_heads)
# padding_mask : (batch_size, 1, 1, key의 문장 길이)
# Q와 K의 곱. 어텐션 스코어 행렬.
matmul_qk = tf.matmul(query, key, transpose_b=True)
# 스케일링
# dk의 루트값으로 나눠준다.
depth = tf.cast(tf.shape(key)[-1], tf.float32)
logits = matmul_qk / tf.math.sqrt(depth)
# 마스킹. 어텐션 스코어 행렬의 마스킹 할 위치에 매우 작은 음수값을 넣는다.
# 매우 작은 값이므로 소프트맥스 함수를 지나면 행렬의 해당 위치의 값은 0이 된다.
if mask is not None:
logits += (mask * -1e9)
# 소프트맥스 함수는 마지막 차원인 key의 문장 길이 방향으로 수행된다.
# attention weight : (batch_size, num_heads, query의 문장 길이, key의 문장 길이)
attention_weights = tf.nn.softmax(logits, axis=-1)
# output : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
output = tf.matmul(attention_weights, value)
return output, attention_weightsclass MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, name="multi_head_attention"):
super(MultiHeadAttention, self).__init__(name=name)
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
# d_model을 num_heads로 나눈 값.
# 논문 기준 : 64
self.depth = d_model // self.num_heads
# WQ, WK, WV에 해당하는 밀집층 정의
self.query_dense = tf.keras.layers.Dense(units=d_model)
self.key_dense = tf.keras.layers.Dense(units=d_model)
self.value_dense = tf.keras.layers.Dense(units=d_model)
# WO에 해당하는 밀집층 정의
self.dense = tf.keras.layers.Dense(units=d_model)
# num_heads 개수만큼 q, k, v를 split하는 함수
def split_heads(self, inputs, batch_size):
inputs = tf.reshape(
inputs, shape=(batch_size, -1, self.num_heads, self.depth))
return tf.transpose(inputs, perm=[0, 2, 1, 3])
def call(self, inputs):
query, key, value, mask = inputs['query'], inputs['key'], inputs[
'value'], inputs['mask']
batch_size = tf.shape(query)[0]
# 1. WQ, WK, WV에 해당하는 밀집층 지나기
# q : (batch_size, query의 문장 길이, d_model)
# k : (batch_size, key의 문장 길이, d_model)
# v : (batch_size, value의 문장 길이, d_model)
# 참고) 인코더(k, v)-디코더(q) 어텐션에서는 query 길이와 key, value의 길이는 다를 수 있다.
query = self.query_dense(query)
key = self.key_dense(key)
value = self.value_dense(value)
# 2. 헤드 나누기
# q : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
# k : (batch_size, num_heads, key의 문장 길이, d_model/num_heads)
# v : (batch_size, num_heads, value의 문장 길이, d_model/num_heads)
query = self.split_heads(query, batch_size)
key = self.split_heads(key, batch_size)
value = self.split_heads(value, batch_size)
# 3. 스케일드 닷 프로덕트 어텐션. 앞서 구현한 함수 사용.
# (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
scaled_attention, _ = scaled_dot_product_attention(query, key, value, mask)
# (batch_size, query의 문장 길이, num_heads, d_model/num_heads)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
# 4. 헤드 연결(concatenate)하기
# (batch_size, query의 문장 길이, d_model)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model))
# 5. WO에 해당하는 밀집층 지나기
# (batch_size, query의 문장 길이, d_model)
outputs = self.dense(concat_attention)
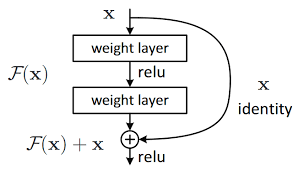
return outputs▶ Layer Normalization & Skip Connection
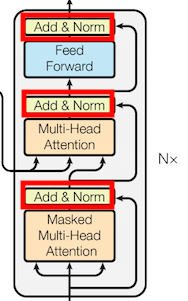
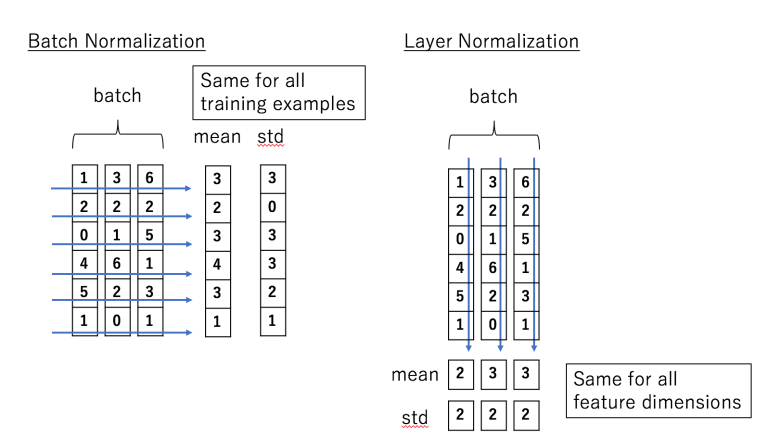
→ Layer Normalization
Layer Normalization ≒ Batch Normalization
→ Skip Connection
역전파 과정에서 정보손실을 줄임
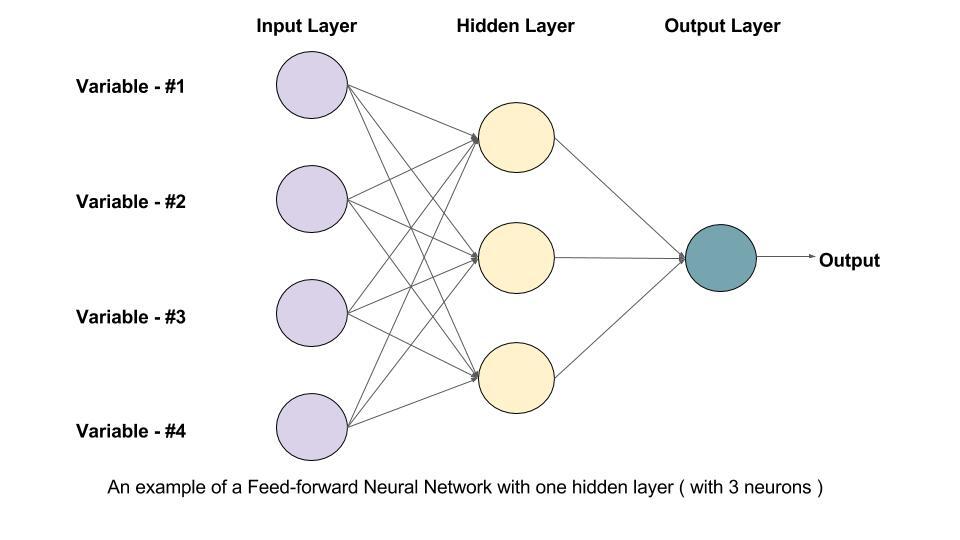
▶ Feed Forward Neural Network ( FFNN )
차원을 다시 원래대로 줄임
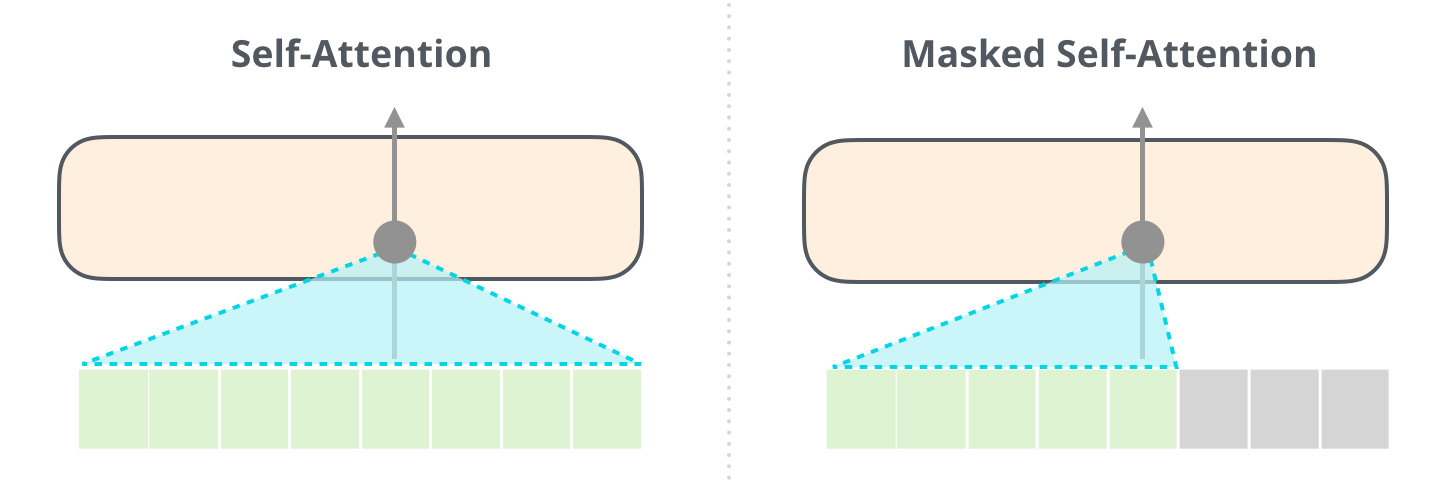
▶ Masked Self - Attention
Self - Attention에 영향을 주지 않도록 Masking ( 가려주고 싶은 요소에 매우 작은 수를 더해줌 )을 해줌
▶ Encoder - Decoder Attention
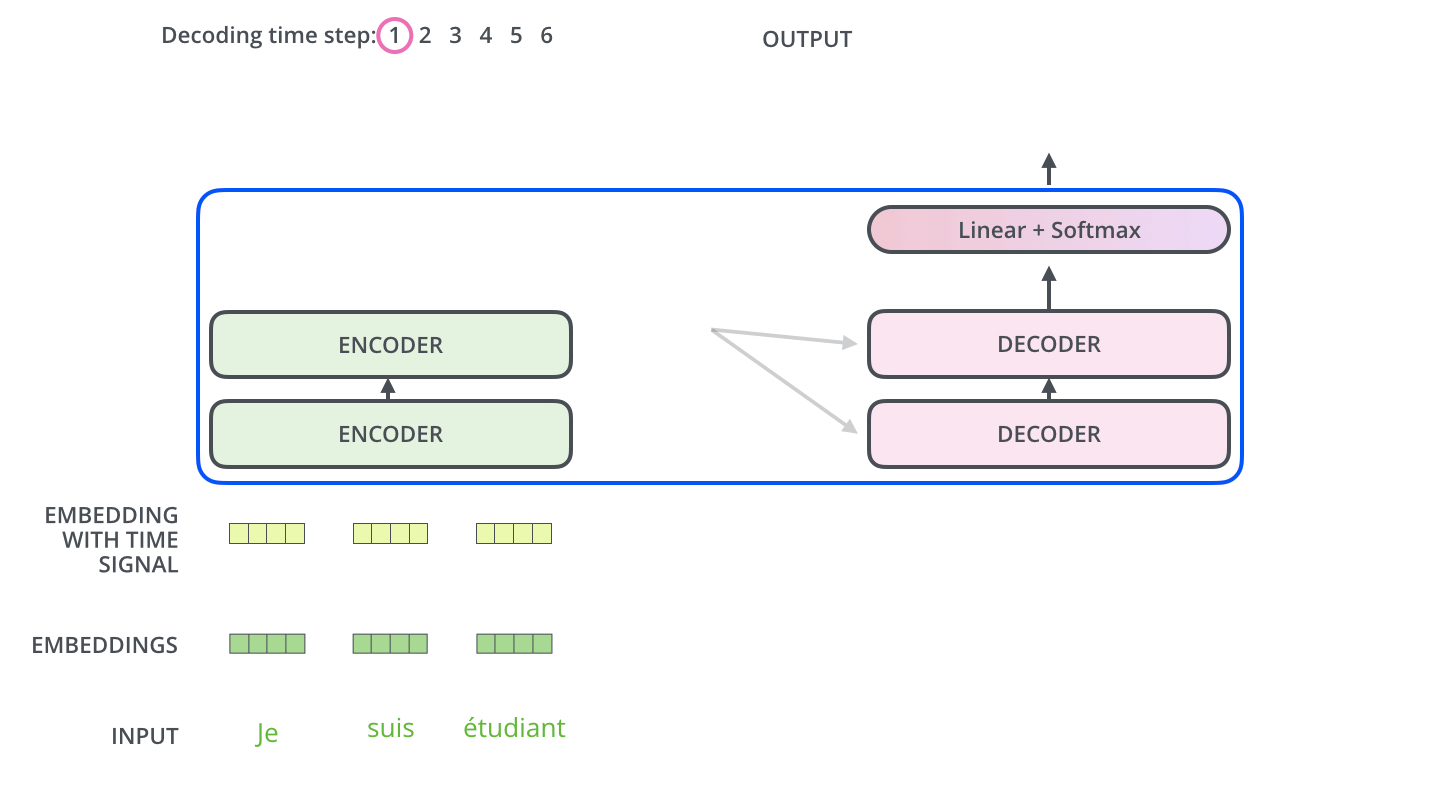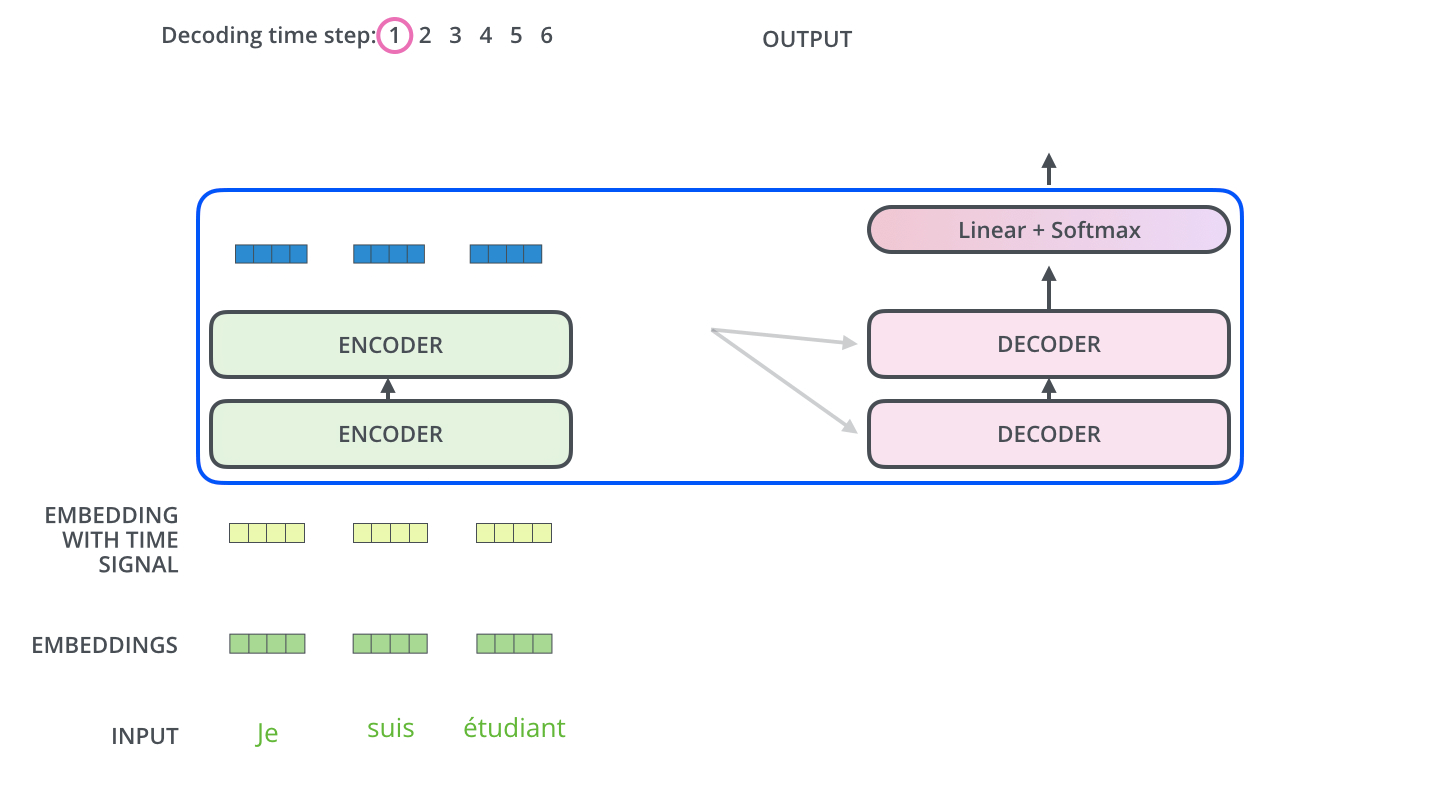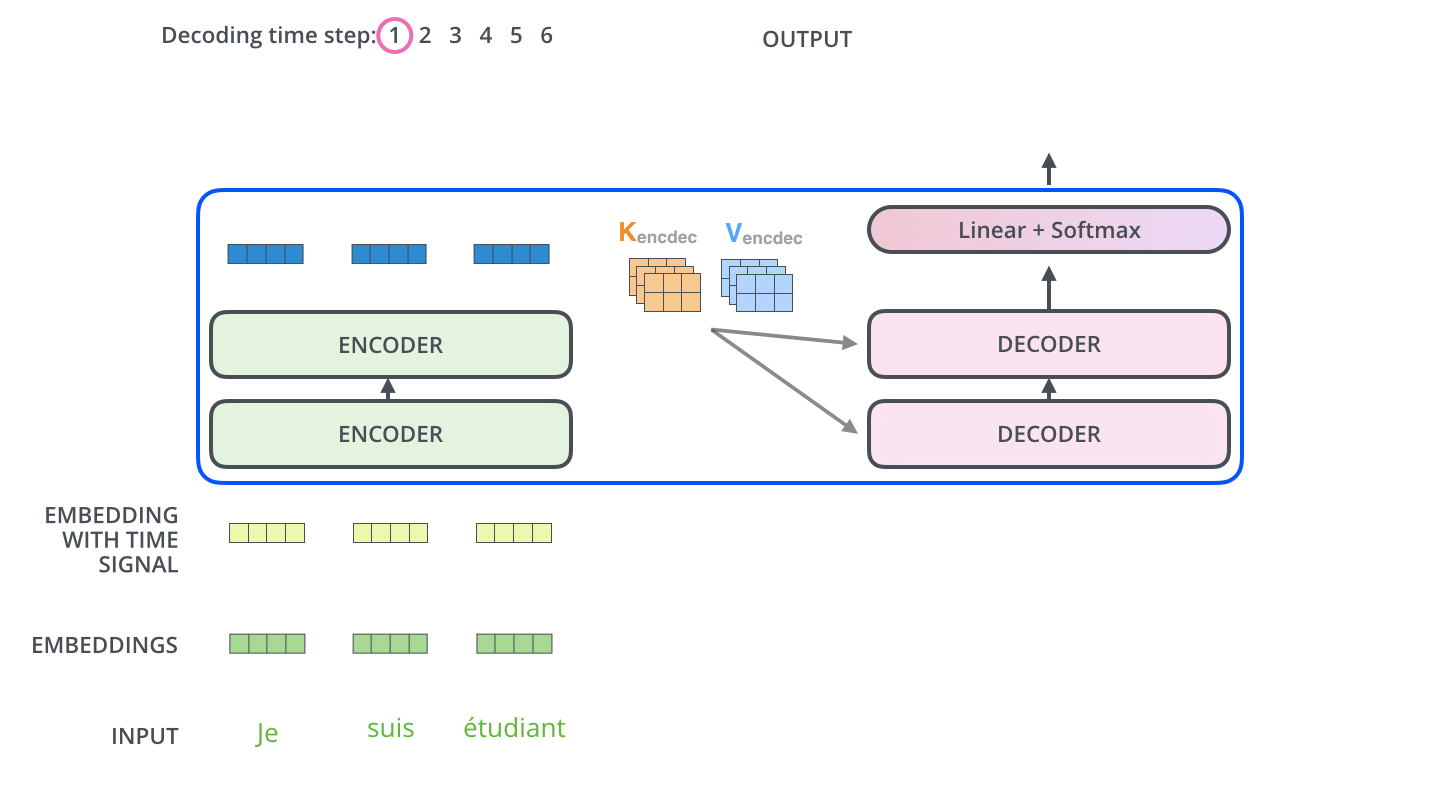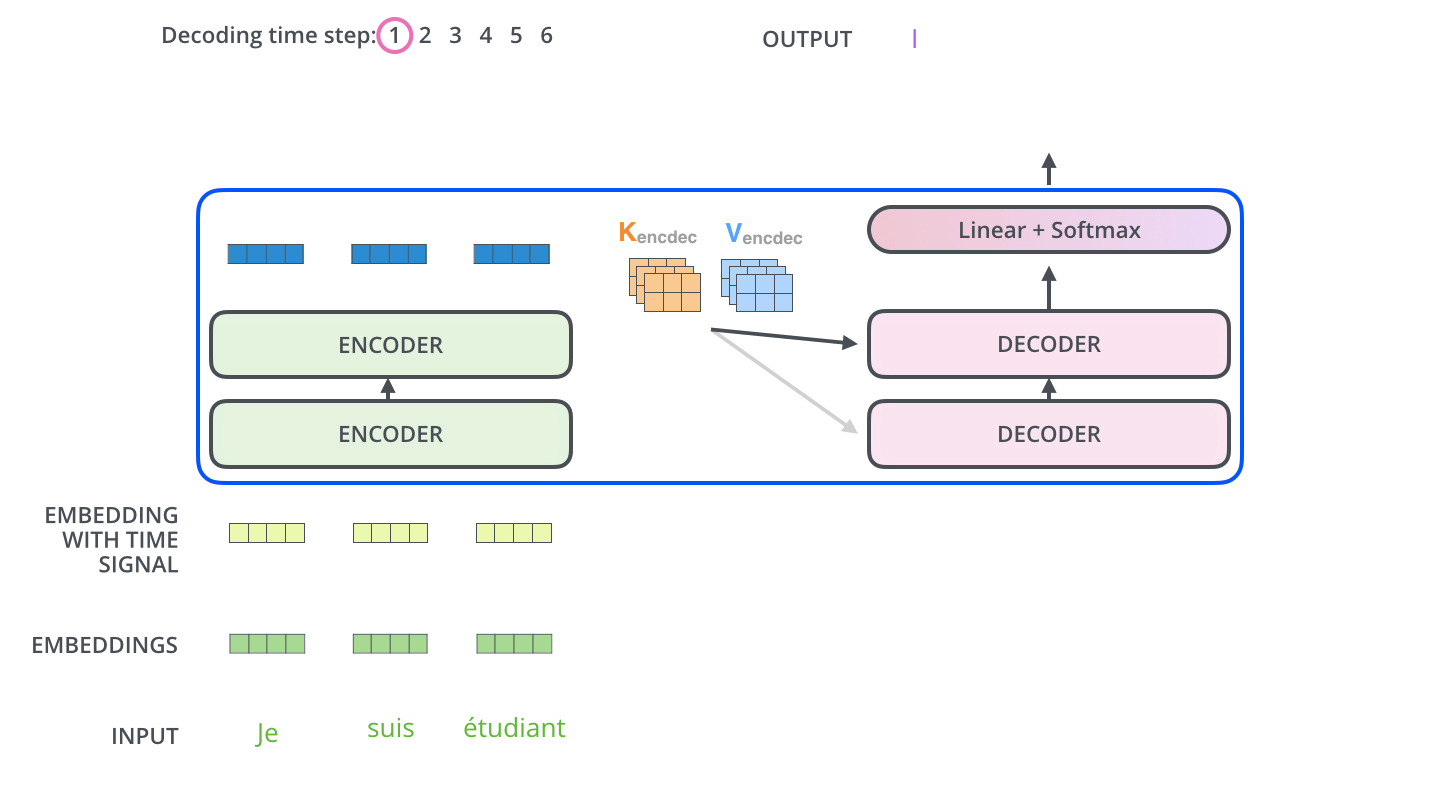
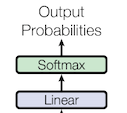
▶ Linear & Softmax Layer
Softmax를 통해 예측할 단어의 확률을 구함
Transformer 코드로 구현 ( Keras )
def transformer(vocab_size, num_layers, dff,
d_model, num_heads, dropout,
name="transformer"):
# 인코더의 입력
inputs = tf.keras.Input(shape=(None,), name="inputs")
# 디코더의 입력
dec_inputs = tf.keras.Input(shape=(None,), name="dec_inputs")
# 인코더의 패딩 마스크
enc_padding_mask = tf.keras.layers.Lambda(
create_padding_mask, output_shape=(1, 1, None),
name='enc_padding_mask')(inputs)
# 디코더의 룩어헤드 마스크(첫번째 서브층)
look_ahead_mask = tf.keras.layers.Lambda(
create_look_ahead_mask, output_shape=(1, None, None),
name='look_ahead_mask')(dec_inputs)
# 디코더의 패딩 마스크(두번째 서브층)
dec_padding_mask = tf.keras.layers.Lambda(
create_padding_mask, output_shape=(1, 1, None),
name='dec_padding_mask')(inputs)
# 인코더의 출력은 enc_outputs. 디코더로 전달된다.
enc_outputs = encoder(vocab_size=vocab_size, num_layers=num_layers, dff=dff,
d_model=d_model, num_heads=num_heads, dropout=dropout,
)(inputs=[inputs, enc_padding_mask]) # 인코더의 입력은 입력 문장과 패딩 마스크
# 디코더의 출력은 dec_outputs. 출력층으로 전달된다.
dec_outputs = decoder(vocab_size=vocab_size, num_layers=num_layers, dff=dff,
d_model=d_model, num_heads=num_heads, dropout=dropout,
)(inputs=[dec_inputs, enc_outputs, look_ahead_mask, dec_padding_mask])
# 다음 단어 예측을 위한 출력층
outputs = tf.keras.layers.Dense(units=vocab_size, name="outputs")(dec_outputs)
return tf.keras.Model(inputs=[inputs, dec_inputs], outputs=outputs, name=name)참고
딥 러닝을 이용한 자연어 처리 입문
728x90
반응형
'AI > Codestates' 카테고리의 다른 글
| [Deep Learning - CV] Beyond Classification ( Segmentation & Object Detection ) (1) | 2022.05.13 |
|---|---|
| [Deep Learning - CV] Convolutional Neural Network ( CNN ) (0) | 2022.05.13 |
| [Deep Learning - NLP] Language Modeling With RNN (0) | 2022.05.09 |
| [Deep Learning - NLP] Distributed Representation (0) | 2022.05.06 |
| [Deep Learning - NLP] Count-based Representation (0) | 2022.05.04 |